Human Body Estimation challenge in computer vision
Understanding why common evaluation metrics are not the final criteria to achieve good results for users. Challenging beliefs for better perception of 3D animations by non-academic.


Understanding why common evaluation metrics are not the final criteria to achieve good results for users. Challenging beliefs for better perception of 3D animations by non-academic.
Introducing challenges of human body estimation in computer vision
Monocular 3D human pose reconstruction is a challenging task of computer vision. This task consists of placing a human 3D body in the correct position and posture according to a single point-of-view image or video. The goal is similar to motion capture, which generally involves a sensor body suit, multiple cameras, and calibration of the environment. Such machine learning technology generalizes and simplifies motion capture to a single-view camera removing all body sensors and calibration; thus generating a 3D animation from just a video. The subject is currently studied by numerous research labs and institutes globally, providing complex machine-learning solutions.
As we are only interested in recreating a human body's pose and not the person's complete identity, we can assimilate the human pose as a 3D skeleton with articulated joints (wrists, knees, etc.). A pose is thus represented by the 3D rotations of the skeleton joints and the pelvis' 3D positions, considered the skeleton's root joint.
The main machine learning paradigm represents an animation as a sequence of skeleton positions. By taking video as an input (which is a sequence of images/frames), we match the skeleton’s pose to every frame. Working with a human skeleton gives a strong assumption on what the algorithm has to learn and greatly restrains the problem compared to generating the vertices’ position of a body mesh.
The most popular skeleton used in research is the SMPL-Body [1] skeleton which comprises 22 joints and comes with a mesh parametrized by a shape vector representing the body shape. An extended version exists, SMPL-X [5], which includes hands, a total of 54 joints on the skeleton, and facial expressions.
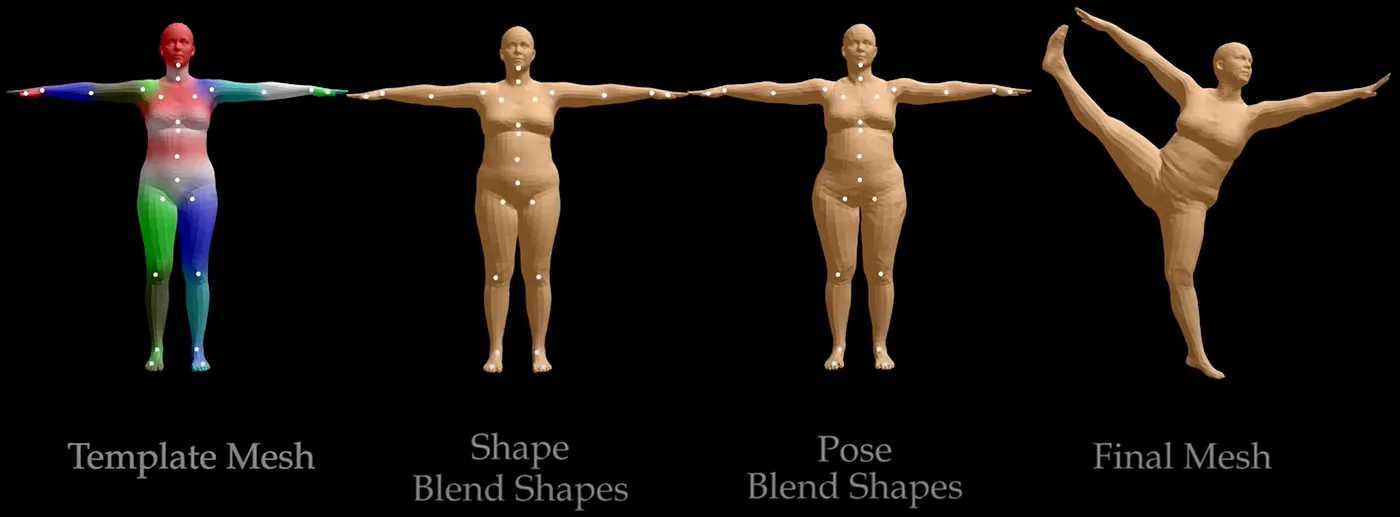
Commonly used evaluation metrics in body estimation
In Deep Learning, neural network models are trained by minimizing a loss function that reflects on one or multiple metrics. Motion capture task is easily adaptable to deep learning as we can train models with a regression loss on the skeleton joints, so minimizing the error between predicted values and ground truth. The main metric used is the Mean Per Joint Position Error (MPJPE) and, as its name indicates, it corresponds to the average distance between the joints of the predicted poses and the joints of the ground truth.
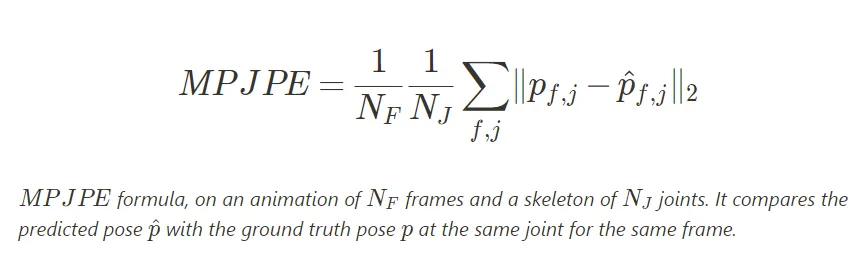
The 3D position of each joint can be deduced from the 3D rotations and the parameters of the skeleton (bones’ lengths, joints hierarchy). This metric is easy to understand and interpret as it represents the mean error, usually in millimeters, of predicted joints.The predicted root position and orientation of the skeleton, the pelvis joint for SMPL, have a substantial impact on the metric as a correct pose prediction in the wrong global position in space would cause this metric to soar. By removing the pelvis position and rotation from the other joints when computing the MPJPE, we can directly evaluate the body pose from the other joints. This operation is more commonly called Procrustes Alignment, thus giving this metric the name PA-MPJPE. It is generally lower than the MPJPE.
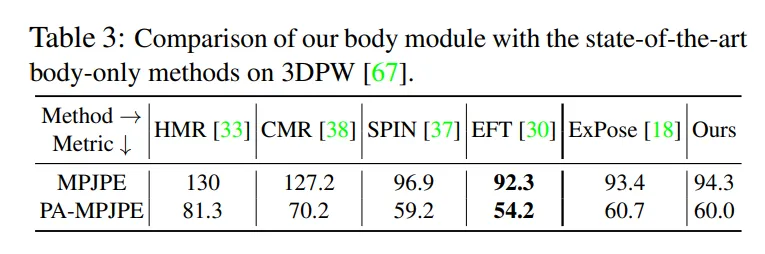
Comparison Table of human body estimation methods by PhysCap [2]
More than joints, we can compare the vertices error (MVE, mean vertices error) of the meshes of the SMPL skeleton [1], as the mesh is parametrized by shape. Some papers focus on the reconstruction of the mesh, for instance, on human-scene interaction.We can also cite the PCK metric, the Percentage of Correct Keypoints. Given a threshold on the Euclidean error of the predicted joint, we can classify the prediction of each joint as correctly predicted or not. The PCK corresponds to the percentage of correctly predicted joints. That means for a threshold of 10mm, the PCK (10mm) corresponds to the proportion of joints predicted to be at less than 10mm from the ground truth. That shifts the view on the problem as a classification one and allows us to compute classification-related metrics such as accuracy or AUC (area under the curve) metric.
Why good metrics don’t necessarily make good animations
Those metrics try to make models predict poses as close as real animation seen in the dataset during training. Thus, results highly depend on the quality of the animation, which is not always perfect and mostly comes from real motion capture with a bit of noise.Some persistent problems are often visible in the resulting animation.Jitter is one of the most obvious ones. It can be easily mitigated by filtering and smoothing algorithms but at the cost of precision and dynamism of the movement.Interpenetration and self contact is also an issue rarely handled in animation generation. A cross-armed human with arms interpenetrating in each other would look glitchy. It is also the case with interpenetration between the feet and the floor or hands and objects.Example of interpenetrationFoot skating is a major issue that needs to be solved to make animations look realistic. It is visible and troubling for every animation, whether it is for sports, dancing, or fighting scene.The video below shows an animation of jumping jacks from MOVI datasets. On the left is the ground truth of the dataset, and on the right, it is the same animation with the grounding algorithm of Kinetix. This technic locks the feet on the ground and at the same level to avoid foot sliding and penetration. The MPJPE on the left is null as it is the ground truth but the right one is modified. Therefore, the MPJPE is not null, and the animation feels more realistic regarding the feet’ contact with the ground.Grounding results by Kinetix.
Finally, realism in animation is about the posture of the body, how natural the movement is, that is proper to humans. We can call this an overall consistency in the animation where we can feel that the dynamism is plausible in real life. Certain aspects are subjective and hard to evaluate for their realism.
Understanding past academic research on body estimation
Academic research papers in 3D human estimation primarily focus on solving a precise issue in realistic animation. While the Applied R&D team needs to create a complete pipeline that addresses most of these issues.In academic research, we can find SimPoe’s [6] research paper from Carnegie Mellon University and Facebook Reality Labs. It gives a foot skating and penetration solution using reinforcement learning controllers in a physics simulation. SimPoe first runs a classic body estimator and refines the resulting animation within a simulator using character controllers to match the body dynamics.
SimPoe [6] Results, an improvement in foot jittering, penetration, and sliding
Moreover, some research papers improve specific points given some assumptions on the input and tackle specific cases. For instance, GLAMR [3], from NVIDIA and Carnegie Mellon University, improves the body estimation of obstructed characters by considering that the camera is moving. It also deals with leg and foot motion by predicting the body trajectory using the body pose estimation. It achieves astounding results with the global position estimation, tracking, and mesh reconstruction of multiple characters from a monocular and dynamic camera estimation.
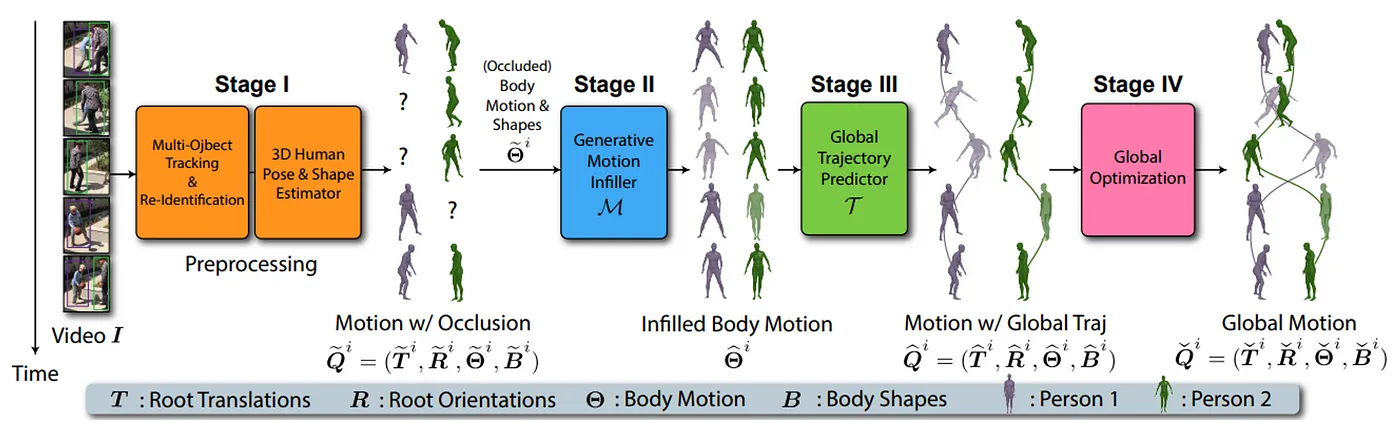
GLAMR [3] pipeline above and a video presenting their results below
This paper presents significant results in trajectory prediction and improved leg motion consistency in a global environment.
We can also cite On Self-Contact and Human Pose [4] from Max Planck Institute and ETH Zürich**, whic**h focuses on improving self-contact and self-penetration. This paper proposes new self-contact datasets and a regressor to correct mesh contact called TUCH. It first predicts the body pose and shape using the Smpl-X [5] skeleton and then detects and optimizes self-contact to create real contact on the resulting mesh.

TUCH [4] results on self-contact
Conclusion
Academic research mainly focuses on improving some specific aspects and resolving precise issues on the subject. Academic papers deal with important points on body poses and dynamism plausibility providing valuable solutions to these matters. However, for applied research, we mainly focus on having good results in most facets of the problem, taking the computation time into account, the realism of output animation, and tackling the main issue for users. To achieve such a goal and create a complete pipeline, we should not rely on a simple machine learning model because main 3D body estimation metrics are not necessarily realistic metrics, but gather and unify these solutions. Developing a one-size-fits-all Artificial Intelligence is the challenge Kinetix tries to solve to democratize access to 3D animations.With the rise in animation demands from video games and virtual worlds, there is a need to build better Machine Learning Models to ensure end users appreciate the results. With the adoption of 3D animations by a larger audience of non-academic researchers, new questions arise. Will the end goal still be to make animations more realistic science-wise or the focus will shift toward developing algorithms for better users’ perception? Which non-academic metrics will emerge as new standards in the industry? Will we observe the development of new algorithms not focused on realistic renderings but on providing smarter customization tools?
Initially published on Medium
References
[1] Loper, Matthew, et al. “SMPL: A skinned multi-person linear model.” ACM transactions on graphics (TOG) 34.6 (2015): 1–16.[2] Shimada, Soshi, et al. “Physcap: Physically plausible monocular 3d motion capture in real-time.” ACM Transactions on Graphics (ToG) 39.6 (2020): 1–16.[3] Yuan, Ye, et al. “GLAMR: Global occlusion-aware human mesh recovery with dynamic cameras.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.[4] Muller, Lea, et al. “On self-contact and human pose.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.[5] Pavlakos, Georgios, et al. “Expressive body capture: 3d hands, face, and body from a single image.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.[6] Yuan, Ye, et al. “Simpoe: Simulated character control for 3d human pose estimation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2021.
Join our newsletter
With Kinetix's SDK & APIs, integrate an AI-powered User-Generated Emote feature in your game with just a few lines of code.

